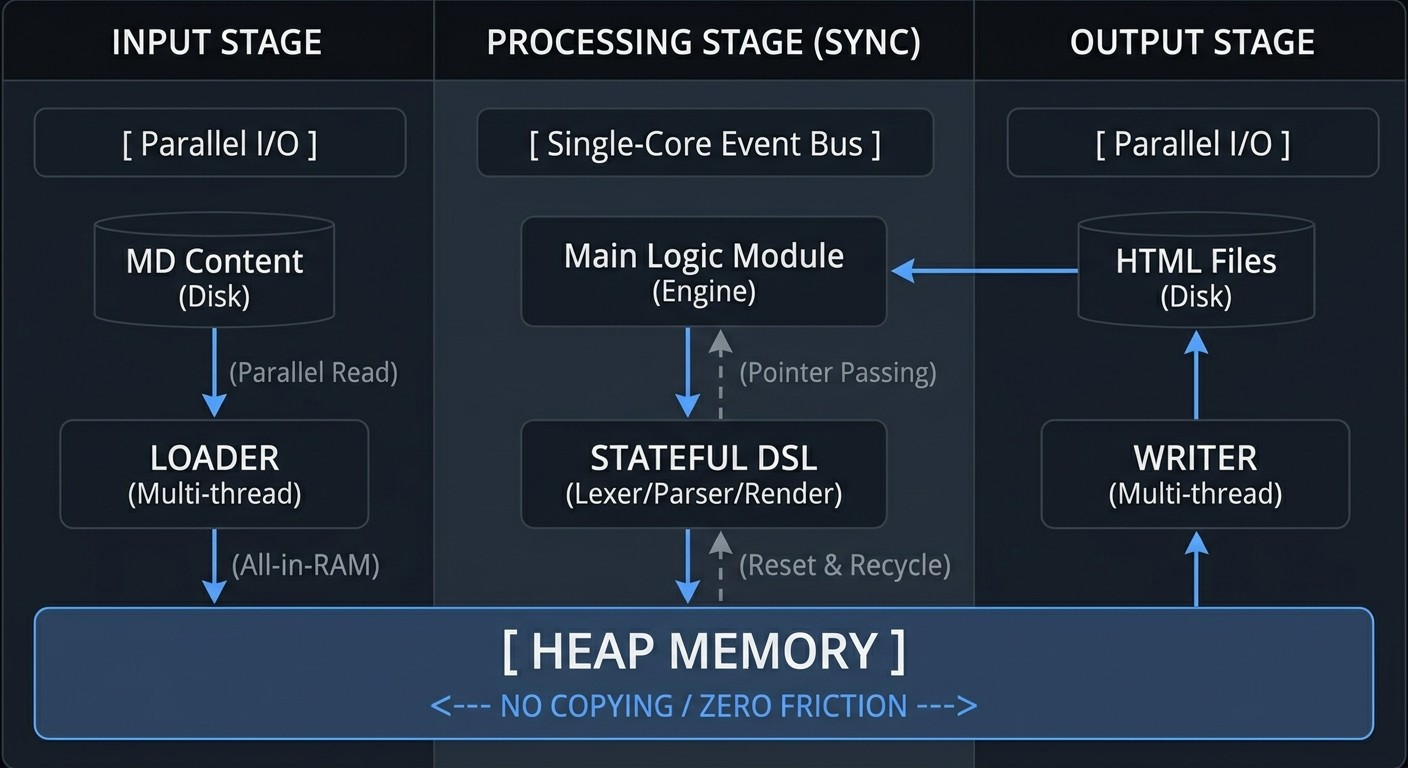
🧠 Core Concepts & Architecture
Mustela isn't just a static site generator. It’s a high-speed data pipeline.
While traditional generators behave like obstacle courses — where data is constantly cloned, transformed, and cleaned up by a garbage collector — Mustela is designed as a frictionless slide. Once data enters the system, it moves toward the output with zero redundant movement.
1. The Three-Phase Pipeline
To achieve maximum throughput, Mustela splits the build process into three distinct, highly optimized stages:
Phase 1: Parallel Ingest (Disk ➔ RAM)
We don't read files one by one. Mustela uses multi-threading to saturate your hardware's I/O bandwidth, pulling all source content into RAM simultaneously.
- The Goal: Eliminate I/O wait times completely.
- The Result: Your entire project becomes a single, unified data object living on the Heap.
Phase 2: Synchronous Event-Bus Core
Once the data is in memory, a single-core event bus takes over for the actual processing.
- Why single-core? It provides absolute deterministic control.
- Zero Overhead: By running the core logic on one thread, we eliminate the need for mutexes (thread-locking) and the risk of race conditions, making the engine "lock-free" and incredibly lean.
Phase 3: Parallel Flush (RAM ➔ Disk)
As the HTML is rendered, it’s handed off to a parallelized worker pool. We 'fire' the data back to disk using 32 concurrent threads—a limit that ensures maximum write stability and saturates SSD bandwidth without overwhelming the operating system's I/O scheduler.
2. The Zero-Copy Principle
Mustela’s speed comes from a simple rule: Don't touch the data unless you have to.
Most engines copy strings from one function to another. Mustela strictly uses Pointer Passing. Once your Markdown is in memory, we pass only its address (pointer). This drastically reduces CPU cycles and energy consumption, as the system never has to allocate memory for the same data twice.
3. Stateful DSL & Memory Recycling
Every time a generator processes a new file, it usually creates a new "environment." Mustela doesn't. We use State Recycling:
- The DSL engine (Lexer/Parser) is allocated once on the heap.
- Between files, we simply reset its internal state instead of destroying and recreating it.
- By reusing "warm" memory, we bypass the heavy cost of constant allocation.
4. Performance: The 5,000 Page Challenge
Mustela isn't just fast; it's engineered for extreme throughput.
Test Environment:
- CPU: Intel(R) Core(TM) i5-8365U @ 1.60GHz (4 cores / 8 threads)
- OS: ChromeOS Flex (Linux Container)
- Storage: SSD
Benchmark Results (Real-world content):
| Metric | Result |
|---|---|
| Files Processed | 5,000 Markdown files |
| Total Build Time | 528 ms (0.5 seconds) |
| Throughput | ~9,470 pages / second |
| Peak RAM Usage | 34.6 MB |
| CPU Efficiency | 101% (Optimized Single-Threaded Core) |
💼 Looking for Enterprise Deep-Dive Metrics?
We have executed a comprehensive stress-test processing 43.22 MB of dense data into a 61.0 MB deployable site with full RSS and Sitemap generation in 904 ms @ 149.3 MB RAM.
👉 [ Download Official Investment Briefing & Technical Case Study PDF ]
Note: Building 5,000 pages in half a second means your site is ready before your monitor can even finish its next refresh cycle.
4.1 Real-world Build Output:
--------------------------------------
Mustela Build Finished
Files: 5000
Time: 528 ms (528633 µs)
--------------------------------------
Command being timed: "mustela build"
User time (seconds): 0.38
System time (seconds): 0.14
Percent of CPU this job got: 101%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:00.52
Maximum resident set size (kbytes): 35456
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 9437
Voluntary context switches: 5515
Involuntary context switches: 193
Exit status: 05. Visualizing the Flow